写在前面: 本文——mysql字符集(character set)和排序规则(collation)的初步总结,源于学习过程中对select length('汉字');的好奇,由于学习阶段及时间问题,部分疑问最终没有很好的解决.暂时不再探究。总结粗糙,理解不精,主要为个人学习过程记录,方便后期复习,仅供网友参考,欢迎提出见解。
MySQL中字符集(character set )指的是由一对对symbol和encoding的对应关系组成的集合(粗略理解为编码方式),排序规则(collation )主要用于指明字符间的比较方式。( MySQL includes character set support that enables you to store data using a variety of character sets and perform comparisons according to a variety of collations. )详见8.0手册第10章总述及10.1节。(本文参考手册皆指官方mysql 8.0手册)
MySQL 8.0 默认的 character set(字符集) and collation(排序规则) 是 utf8mb4 和 utf8mb4_0900_ai_ci, 具体来讲可以分别指定 :服务器(server),数据库(database),表(table),列(column)以及原义字符串(character string literal )的character set 和对应的 collation
- 1.1 查看MySQL支持的[所有的]character set 和collation
show character set ; show collation ;两者都可添加限定条件语句:like或where clause#character set 可以简写为charset;手册10.3.1 节详细介绍了character set 和 collation 的命名规则- 在MySQL中,全部的charset 与collation的信息都存放在information_schema库中。除上述方法外,还可进入information_schema库中查看CHARACTER_SETS与COLLATIONS表
use information_schema;select * from character_sets,collations [where clause];
- 1.2查看系统当前设置的各种字符集/排序规则
show [session ]variables like 'char%'/'collation%';
或select * from performance_schema.session_variables where variable_name like 'character_set_%';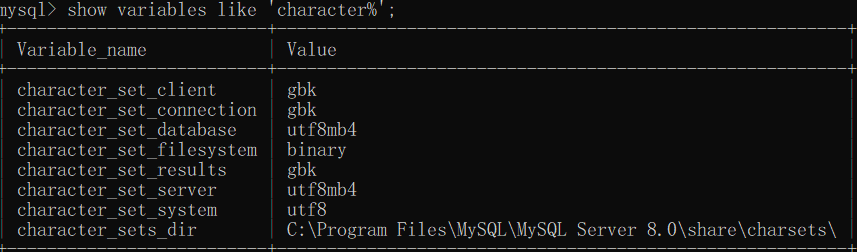
表1 - 1.4 collation 的命名规则参见手册10.3.1节。
- 1.1 查看MySQL支持的[所有的]character set 和collation
1.5可解如下困惑:
- 1.4.1
select length('张'); mysql > 2
在此查询中,汉字'张' 即原义(或译为常量?)字符串(见手册10.3.6节/下文2),因在查询时没有特别指定character set 以及collation ,故为默认值。由表1:character_set_connection | gbk可知,编码方式为GBK,而GBK编码使用两个字节来标识汉字字符码,所以上述运行结果为 2 。- 1.4.2
use pra ;select legnth(stu_name) from stuinfo where stuid = 1; mysql> 6
字符串' 张三 ' 占用6个字节,故单个汉字(字符)占用3个字节。可以解释为:- ① 因:创建pra表中的各字段时,未特意指定编码类型,故根据手册10.3.5可知编码方式应为其所属的table的编码类型,使用3.2命令查看,为默认的utf8b4
- ② 手册10.9.1节详细介绍了utf8b4字符集类型,指明了:

- 在编码 BMP字符时utf8mb4与utf8/utf8mb3 可以大致等同,每个字符编码存储都占用相同的字节数(英文字符1个字节,汉字3个字节);走出了各种论坛中的不精确表达" utf8mb4存储汉字占用4个字节,utf8mb3占用3个字节 " 的思维定势。
- 在编码SMP字符时,utf8mb4才占用4个字节(当然,utf8/utf8mb3 不支持存储SMP字符,这中字符集类型很快会被官方弃用)
- 两种类型同时存在时,一般会自动转化为utf4mb4类型。
- BMP字符可以粗略理解为常用字符,SMP理解为不常用字符,比如emoj符号。
- ③ 详细的各种类型的字符编码,可参见博客园:字符串,那些事
- 1.4.2
- 1.4.1
Character string literal 译为原义字符串,指的是在Query clause 中的字符串,脱离于表,与表无关。手册10.3.6节。
2.1 形式为
[_charset_name]'string' [COLLATE collation_name];2.2 解释:
The _charset_name expression is formally called an introducer. It tells the parser, "the string that follows uses character set charset_name."。2.3

2.4 困惑 在系统CMD窗口
①select length('你') ;mysql>2
②select length(_utf8mb4 '你') ;mysql>2
运行结果不变,通过命令1.3(表1)可看到character_set_connection = gbk ,①可理解,那么②呢?
字符串'你'之前的 introducer 无效吗?2.2解释It tells the parser, "the string that follows uses character set charset_name.到底什么意思,中间还涉及什么过程。2.4.1 换用了MySQL Client CMD 运行,连接字符集同样为gbk,运行结果也都为 2 。换用navicat命令行执行,连接字符集变为utf8mb4 (client ,results字符集也都变为utf8mb4),两条select语句执行结果都变为 3 (第二条的introducer 修改为 _gbk)。
结论:introducer 对于字符串本身没有影响,还是受character_set_connection或其他变量 影响 (说法不准确)2.4.2 查阅手册10.3.8 introducer相关知识:
An introducer does not change the string to the introducer character set like CONVERT() would do. It does not change the string value, although padding may occur. The introducer is just a signal. (不太理解) ① 查阅12.11节 Cast Functions and operators 的 convert(expr using transcoding_name)函数 :
converts data between different character sets.,貌似是真正的转换。 ② 这不同于introducer中的表述:
It does not change the string value, although padding may occur. The introducer is just a signal(它到底是干嘛的) ③ 运行
select length(convert('你' using utf8mb4)); mysql> 3,而此时character_set_connection 仍然为gbk
那么结合①,到底introducer 到底发挥什么样的作用,character_set_connection 发挥什么样的作用, ?2.4.3 查看手册10.4节 Connection character set and collation ,该部分涉及到了客户端与服务器的交互过程中的编码转换过程。
- 客户端与服务器的交互大致涉及三个变量:character_set_client , character_set_conneciton , character_set_results.
- 整体过程可粗略解释如下,更详细可参考七把刀简书博文。
① 服务器从客户端接收以character_set_client 编码的语句(statements);
② 服务器将接收到的statements 从character_set_client 转译(translate/convert)为character_set _connection.
此处提到:For string literals that have an introducer such as _utf8mb4 or _latin2, the introducer determines the character set. (怎么determine呢,上面没感觉determine呀) 又提及:collation_connection 对于literal strings 的比较是重要的,对于表列中的字符串的比 较无关紧要 。
③ server 将执行结果以character_set_results 的编码形式传回client④:在七把刀简书博文中的介绍部分不能理解:指定introducer 后的解释。
- 无法类比当前所纠结的查询的实际过程。直接的一个函数到达服务器后是如何执行的。过程中的编码是如何转换的。考虑查看源码?
2.4.4 总: 与当下学习任务关联度不大,在该问题上耗时过长,不再花费时间纠结。粗略结论:①introducer 在整个过程中没有起到多大作用 ;
② convert函数可以实实在在的看到效果;
③单独或一同修改(client,connection,results)并结合三者(无introducer ,有introducer, convert转换)试验后,效果迷离,心累,不再探究;
④问题关键还是没有理解introducer, 各字符集,以及客户端与服务器交互时的编码转换过程。日后涉及,在经验积累的基础上再行探究。
分类
3.1 字段级别
- 查看某一 table 所有字段的详细信息(含排序规则collation一列(根据10.3.1中的collation命名规则易知对应的character set))
show full columns from table_name; - 查看当前选中的数据库中所有表的信息(含table_name , Engine, version , create_time , update_time, collation 等)
show table status [ from databse_name / where name like '%name%']; - 修改字段的charset 和 collation
alter table table_name modify filed_name field_type field_charset_name;
- 查看某一 table 所有字段的详细信息(含排序规则collation一列(根据10.3.1中的collation命名规则易知对应的character set))
3.2 表级别
查看建表语句(最新的,含修改过的 )( 其中包含当前表设置的默认的character set ,collation信息)
show create table table_name;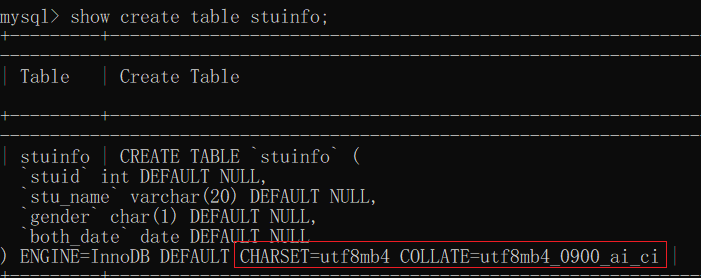
修改表的charset和collation
alter table table_name charset charset_name;
3.3 数据库级别
查看当前数据库默认的字符集,以及排序规则
show variables where variable_name = 'character_set_database'use database_name;select @@character_set_database,@@collation_database;select default_character_set_name,default_collation_namefrom information_shema.schematawhere shcema_name = 'db_name';
(可能这种方法涉及当前用户的权限问题,未查证)
查看建数据库语句,从而了解当前数据库默认的字符集,以及排序规则。
show create database database_name修改数据库的character set 和collation
alter database database_name charset utf8mb4
3.4 服务器级别
- 查看服务器字符集配置
show variables where variable_name = 'character_set_server ;'
也可以简单使用show variables like 'char%'; - 配置 server 的默认charset 和collation (详细参见10.3.2节)
- 永久性配置:修改my.ini文件中的mysqld --character-set-server=utf8mb4 ,重启MySQL服务。(my.ini文件一般位于C盘 Program Files或者Programdata Files文件夹下的mysql目录下)
- 暂时配置:命令行输入:
set character_set_server= utf8mb4; - 手册中还介绍了cmke 命令。
- 查看服务器字符集配置
3.5 查看**connection , client , results ** 字符集,排序规则
例如 : select @@character_set_connection,@@collation_connetcion;
或者:show variables like 'char%' ;
4.其他
函数 length(),char_length(),character_length() 区别参见手册12 章 Functions and operators 。
手册13.7节Database Adminstration Statement 的13.7.6.3 介绍了Set Names Statements.
set names('charset_name' [collate 'collation_name'] | default);- 该语句将三个session 系统变量 character_set_client , character_set_connection , character_set_results 同时设置为了指定的字符集 charset_name ,collate 语句可选。执行后可使用1.3命令查看效果。(该设置仅当次会话中有效)
- 可以使用default值恢复默认映射。默认值取决于服务器配置
The default mapping can be restored by using a value of DEFAULT. The default depends on the server configuration
细节及注意点,查看手册。博客set name statements总结详细,可参考。
总结粗糙,理解不精,日后更新完善。欢迎提出见解。
原文转载:http://www.shaoqun.com/a/512283.html
铭宣海淘:https://www.ikjzd.com/w/1551
aca:https://www.ikjzd.com/w/1371
写在前面:本文——mysql字符集(characterset)和排序规则(collation)的初步总结,源于学习过程中对selectlength('汉字');的好奇,由于学习阶段及时间问题,部分疑问最终没有很好的解决.暂时不再探究。总结粗糙,理解不精,主要为个人学习过程记录,方便后期复习,仅供网友参考,欢迎提出见解。MySQL中字符集(characterset)指的是由一对对sy
飞书互动:飞书互动
易麦:易麦
深圳宝安区科技馆怎么样?有什么玩的?怎么走?:深圳宝安区科技馆怎么样?有什么玩的?怎么走?
探寻中国最美休闲城市组图 :探寻中国最美休闲城市组图
春节九寨沟住宿信息 :春节九寨沟住宿信息
No comments:
Post a Comment