Apache Hudi使用简介
目录- Apache Hudi使用简介
- 数据实时处理和实时的数据
- 业务场景和技术选型
- Apache hudi简介
- 使用Aapche Hudi整体思路
- Hudi表数据结构
- 数据文件
- .hoodie文件
- Hudi记录Id
- COW和MOR
- Copy On Write Table
- Merge On Read Table
- 基于hudi的代码实现
- binlog数据写入Hudi表
- 历史数据同步以及表元数据同步至hive
- 同步历史数据至hudi表
- 同步hudi表结构至hive meta
- 一些踩坑
- hive相关配置
- spark streaming的一些调优
- 未来改进
- 参考资料
数据实时处理和实时的数据
实时分为处理的实时和数据的实时
即席分析是要求对数据实时的处理,马上要得到对应的结果
Flink、Spark Streaming是用来对实时数据的实时处理,数据要求实时,处理也要迅速
数据不实时,处理也不及时的场景则是我们的数仓T+1数据
而本文探讨的Apache Hudi,对应的场景是数据的实时,而非处理的实时。它旨在将Mysql中的时候以近实时的方式映射到大数据平台,比如Hive中。
业务场景和技术选型
传统的离线数仓,通常数据是T+1的,不能满足对当日数据分析的需求
而流式计算一般是基于窗口,并且窗口逻辑相对比较固定。
而笔者所在的公司有一类特殊的需求,业务分析比较熟悉现有事务数据库的数据结构,并且希望有很多即席分析,这些分析包含当日比较实时的数据。惯常他们是基于Mysql从库,直接通过Sql做相应的分析计算。但很多时候会遇到如下障碍
- 数据量较大、分析逻辑较为复杂时,Mysql从库耗时较长
- 一些跨库的分析无法实现
因此,一些弥合在OLTP和OLAP之间的技术框架出现,典型有TiDB。它能同时支持OLTP和OLAP。而诸如Apache Hudi和Apache Kudu则相当于现有OLTP和OLAP技术的桥梁。他们能够以现有OLTP中的数据结构存储数据,支持CRUD,同时提供跟现有OLAP框架的整合(如Hive,Impala),以实现OLAP分析
Apache Kudu,需要单独部署集群。而Apache Hudi则不需要,它可以利用现有的大数据集群比如HDFS做数据文件存储,然后通过Hive做数据分析,相对来说更适合资源受限的环境
Apache hudi简介
使用Aapche Hudi整体思路
Hudi 提供了Hudi 表的概念,这些表支持CRUD操作。我们可以基于这个特点,将Mysql Binlog的数据重放至Hudi表,然后基于Hive对Hudi表进行查询分析。数据流向架构如下
Hudi表数据结构
Hudi表的数据文件,可以使用操作系统的文件系统存储,也可以使用HDFS这种分布式的文件系统存储。为了后续分析性能和数据的可靠性,一般使用HDFS进行存储。以HDFS存储来看,一个Hudi表的存储文件分为两类。

- 包含
_partition_key相关的路径是实际的数据文件,按分区存储,当然分区的路径key是可以指定的,我这里使用的是_partition_key - .hoodie 由于CRUD的零散性,每一次的操作都会生成一个文件,这些小文件越来越多后,会严重影响HDFS的性能,Hudi设计了一套文件合并机制。 .hoodie文件夹中存放了对应的文件合并操作相关的日志文件。
数据文件
Hudi真实的数据文件使用Parquet文件格式存储
.hoodie文件
Hudi把随着时间流逝,对表的一系列CRUD操作叫做Timeline。Timeline中某一次的操作,叫做Instant。Instant包含以下信息
- Instant Action 记录本次操作是一次数据提交(COMMITS),还是文件合并(COMPACTION),或者是文件清理(CLEANS)
- Instant Time 本次操作发生的时间
- state 操作的状态,发起(REQUESTED),进行中(INFLIGHT),还是已完成(COMPLETED)
.hoodie文件夹中存放对应操作的状态记录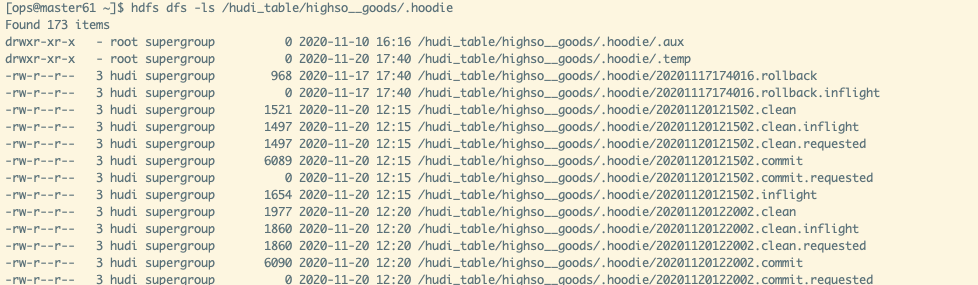
Hudi记录Id
hudi为了实现数据的CRUD,需要能够唯一标识一条记录。hudi将把数据集中的唯一字段(record key ) + 数据所在分区 (partitionPath) 联合起来当做数据的唯一键
COW和MOR
基于上述基础概念之上,Hudi提供了两类表格式COW和MOR。他们会在数据的写入和查询性能上有一些不同
Copy On Write Table
简称COW。顾名思义,他是在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据。正在读数据的请求,读取的是是近的完整副本,这类似Mysql 的MVCC的思想。
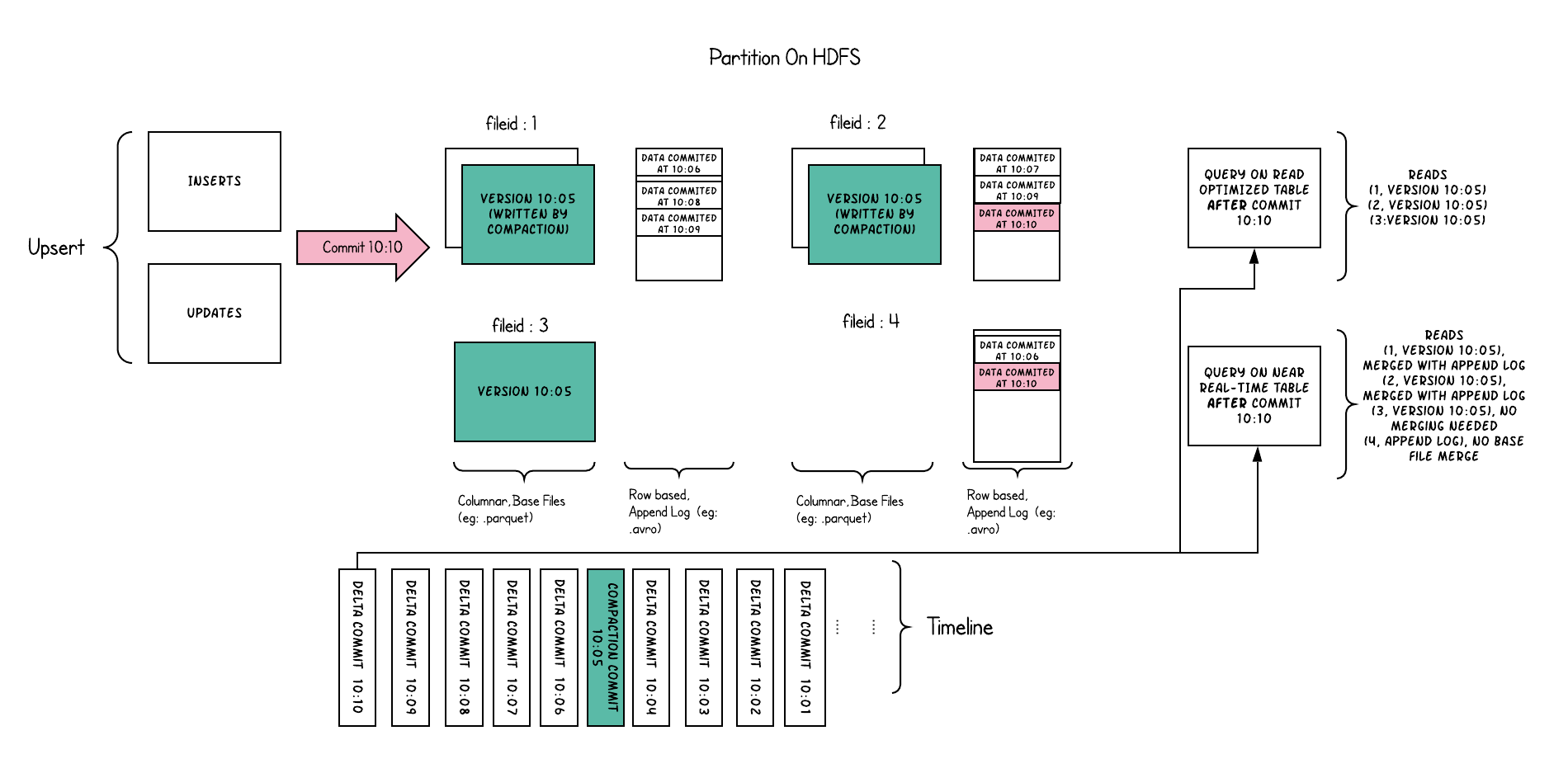
上图中,每一个颜色都包含了截至到其所在时间的所有数据。老的数据副本在超过一定的个数限制后,将被删除。这种类型的表,没有compact instant,因为写入时相当于已经compact了。
- 优点 读取时,只读取对应分区的一个数据文件即可,较为高效
- 缺点 数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时。且由于耗时,读请求读取到的数据相对就会滞后
Merge On Read Table
简称MOR。新插入的数据存储在delta log 中。定期再将delta log合并进行parquet数据文件。读取数据时,会将delta log跟老的数据文件做merge,得到完整的数据返回。当然,MOR表也可以像COW表一样,忽略delta log,只读取最近的完整数据文件。下图演示了MOR的两种数据读写方式
- 优点 由于写入数据先写delta log,且delta log较小,所以写入成本较低
- 缺点 需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta log 和 老数据文件合并
基于hudi的代码实现
我在github上放置了基于Hudi的封装实现,对应的源码地址为 https://github.com/wanqiufeng/hudi-learn。
binlog数据写入Hudi表
- binlog-consumer分支使用Spark streaming消费kafka中的Binlog数据,并写入Hudi表。Kafka中的binlog是通过阿里的Canal工具同步拉取的。程序入口是CanalKafkaImport2Hudi,它提供了一系列参数,配置程序的执行行为
| 参数名 | 含义 | 是否必填 | 默认值 |
|---|---|---|---|
--base-save-path | hudi表存放在HDFS的基础路径,比如hdfs://192.168.16.181:8020/hudi_data/ | 是 | 无 |
--mapping-mysql-db-name | 指定处理的Mysql库名 | 是 | 无 |
--mapping-mysql-table-name | 指定处理的Mysql表名 | 是 | 无 |
--store-table-name | 指定Hudi的表名 | 否 | 默认会根据--mapping-mysql-db-name和--mapping-mysql-table-name自动生成。假设--mapping-mysql-db-name 为crm,--mapping-mysql-table-name为order。那么最终的hudi表名为crm__order |
--real-save-path | 指定hudi表最终存储的hdfs路径 | 否 | 默认根据--base-save-path和--store-table-name自动生成,生成格式为'--base-save-path'+'/'+'--store-table-name' ,推荐默认 |
--primary-key | 指定同步的mysql表中能唯一标识记录的字段名 | 否 | 默认id |
--partition-key | 指定mysql表中可以用于分区的时间字段,字段必须是timestamp 或dateime类型 | 是 | 无 |
--precombine-key | 最终用于配置hudi的hoodie.datasource.write.precombine.field | 否 | 默认id |
--kafka-server | 指定Kafka 集群地址 | 是 | 无 |
--kafka-topic | 指定消费kafka的队列 | 是 | 无 |
--kafka-group | 指定消费kafka的group | 否 | 默认在存储表名前加'hudi'前缀,比如'hudi_crm__order' |
--duration-seconds | 由于本程序使用Spark streaming开发,这里指定Spark streaming微批的时长 | 否 | 默认10秒 |
一个使用的demo如下
/data/opt/spark-2.4.4-bin-hadoop2.6/bin/spark-submit --class com.niceshot.hudi.CanalKafkaImport2Hudi \ --name hudi__goods \ --master yarn \ --deploy-mode cluster \ --driver-memory 512m \ --executor-memory 512m \ --executor-cores 1 \ --num-executors 1 \ --queue hudi \ --conf spark.executor.memoryOverhead=2048 \ --conf "spark.executor.extraJavaOptions=-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=\tmp\hudi-debug" \ --conf spark.core.connection.ack.wait.timeout=300 \ --conf spark.locality.wait=100 \ --conf spark.streaming.backpressure.enabled=true \ --conf spark.streaming.receiver.maxRate=500 \ --conf spark.streaming.kafka.maxRatePerPartition=200 \ --conf spark.ui.retainedJobs=10 \ --conf spark.ui.retainedStages=10 \ --conf spark.ui.retainedTasks=10 \ --conf spark.worker.ui.retainedExecutors=10 \ --conf spark.worker.ui.retainedDrivers=10 \ --conf spark.sql.ui.retainedExecutions=10 \ --conf spark.yarn.submit.waitAppCompletion=false \ --conf spark.yarn.maxAppAttempts=4 \ --conf spark.yarn.am.attemptFailuresValidityInterval=1h \ --conf spark.yarn.max.executor.failures=20 \ --conf spark.yarn.executor.failuresValidityInterval=1h \ --conf spark.task.maxFailures=8 \ /data/opt/spark-applications/hudi_canal_consumer/hudi-canal-import-1.0-SNAPSHOT-jar-with-dependencies.jar --kafka-server local:9092 --kafka-topic dt_streaming_canal_xxx --base-save-path hdfs://192.168.2.1:8020/hudi_table/ --mapping-mysql-db-name crm --mapping-mysql-table-name order --primary-key id --partition-key createDate --duration-seconds 1200历史数据同步以及表元数据同步至hive
history_import_and_meta_sync 分支提供了将历史数据同步至hudi表,以及将hudi表数据结构同步至hive meta的操作
同步历史数据至hudi表
这里采用的思路是
- 将mysql全量数据通过注入sqoop等工具,导入到hive表。
- 然后采用分支代码中的工具HiveImport2HudiConfig,将数据导入Hudi表
HiveImport2HudiConfig提供了如下一些参数,用于配置程序执行行为
| 参数名 | 含义 | 是否必填 | 默认值 |
|---|---|---|---|
--base-save-path | hudi表存放在HDFS的基础路径,比如hdfs://192.168.16.181:8020/hudi_data/ | 是 | 无 |
--mapping-mysql-db-name | 指定处理的Mysql库名 | 是 | 无 |
--mapping-mysql-table-name | 指定处理的Mysql表名 | 是 | 无 |
--store-table-name | 指定Hudi的表名 | 否 | 默认会根据--mapping-mysql-db-name和--mapping-mysql-table-name自动生成。假设--mapping-mysql-db-name 为crm,--mapping-mysql-table-name为order。那么最终的hudi表名为crm__order |
--real-save-path | 指定hudi表最终存储的hdfs路径 | 否 | 默认根据--base-save-path和--store-table-name自动生成,生成格式为'--base-save-path'+'/'+'--store-table-name' ,推荐默认 |
--primary-key | 指定同步的hive历史表中能唯一标识记录的字段名 | 否 | 默认id |
--partition-key | 指定hive历史表中可以用于分区的时间字段,字段必须是timestamp 或dateime类型 | 是 | 无 |
--precombine-key | 最终用于配置hudi的hoodie.datasource.write.precombine.field | 否 | 默认id |
--sync-hive-db-name | 全量历史数据所在hive的库名 | 是 | 无 |
--sync-hive-table-name | 全量历史数据所在hive的表名 | 是 | 无 |
--hive-base-path | hive的所有数据文件存放地址,需要参看具体的hive配置 | 否 | /user/hive/warehouse |
--hive-site-path | hive-site. | 是 | 无 |
--tmp-data-path | 程序执行过程中临时文件存放路径。一般默认路径是/tmp。有可能出现/tmp所在磁盘太小,而导致历史程序执行失败的情况。当出现该情况时,可以通过该参数自定义执行路径 | 否 | 默认操作系统临时目录 |
一个程序执行demo
nohup java -jar hudi-learn-1.0-SNAPSHOT.jar --sync-hive-db-name hudi_temp --sync-hive-table-name crm__wx_user_info --base-save-path hdfs://192.168.2.2:8020/hudi_table/ --mapping-mysql-db-name crm --mapping-mysql-table-name "order" --primary-key "id" --partition-key created_date --hive-site-path /etc/lib/hive/conf/hive-site.同步hudi表结构至hive meta
需要将hudi的数据结构和分区,以hive外表的形式同步至Hive meta,才能是Hive感知到hudi数据,并通过sql进行查询分析。Hudi本身在消费Binlog进行存储时,可以顺带将相关表元数据信息同步至hive。但考虑到每条写入Apache Hudi表的数据,都要读写Hive Meta ,对Hive的性能可能影响很大。所以我单独开发了HiveMetaSyncConfig工具,用于同步hudi表元数据至Hive。考虑到目前程序只支持按天分区,所以同步工具可以一天执行一次即可。参数配置如下
| 参数名 | 含义 | 是否必填 |默认值|
| :-------- | --------😐 :------: |
| --hive-db-name| 指定hudi表同步至哪个hive数据库| 是| 无 |
| --hive-table-name| 指定hudi表同步至哪个hive表 | 是 |无 |、
| --hive-jdbc-url| 指定hive meta的jdbc链接地址,例如jdbc:hive2://192.168.16.181:10000| 是|无 |
| --hive-user-name| 指定hive meta的链接用户名| 否 |默认hive |
| --hive-pwd| 指定hive meta的链接密码 | 否 |默认hive |
| --hudi-table-path| 指定hudi表所在hdfs的文件路径| 是 |无 |
| --hive-site-path| 指定hive的hive-site.
一个程序执行demo
java -jar hudi-learn-1.0-SNAPSHOT.jar --hive-db-name streaming --hive-table-name crm__order --hive-user-name hive --hive-pwd hive --hive-jdbc-url jdbc:hive2://192.168.16.181:10000 --hudi-table-path hdfs://192.168.16.181:8020/hudi_table/crm__order --hive-site-path /lib/hive/conf/hive-site.一些踩坑
hive相关配置
有些hive集群的hive.input.format配置,默认是org.apache.hadoop.hive.ql.io.CombineHiveInputFormat,这会导致挂载Hudi数据的Hive外表读取到所有Hudi的Parquet数据,从而导致最终的读取结果重复。需要将hive的format改为org.apache.hadoop.hive.ql.io.HiveInputFormat,为了避免在整个集群层面上更改对其余离线Hive Sql造成不必要的影响,建议只对当前hive session设置set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
spark streaming的一些调优
由于binlog写入Hudi表的是基于Spark streaming实现的,这里给出了一些spark 和spark streaming层面的配置,它能使整个程序工作更稳定
| 配置 | 含义 |
|---|---|
| spark.streaming.backpressure.enabled=true | 启动背压,该配置能使Spark Streaming消费速率,基于上一次的消费情况,进行调整,避免程序崩溃 |
| spark.ui.retainedJobs=10 spark.ui.retainedStages=10 spark.ui.retainedTasks=10 spark.worker.ui.retainedExecutors=10 spark.worker.ui.retainedDrivers=10 spark.sql.ui.retainedExecutions=10 | 默认情况下,spark 会在driver中存储一些spark 程序执行过程中各stage和task的历史信息,当driver内存过小时,可能使driver崩溃,通过上述参数,调节这些历史数据存储的条数,从而减小对内层使用 |
| spark.yarn.maxAppAttempts=4 | 配置当driver崩溃后,尝试重启的次数 |
| spark.yarn.am.attemptFailuresValidityInterval=1h | 假若driver执行一周才崩溃一次,那我们更希望每次都能重启,而上述配置在累计到重启4次后,driver就再也不会被重启,该配置则用于重置maxAppAttempts的时间间隔 |
| spark.yarn.max.executor.failures=20 | executor执行也可能失败,失败后集群会自动分配新的executor, 该配置用于配置允许executor失败的次数,超过次数后程序会报(reason: Max number of executor failures (400) reached),并退出 |
| spark.yarn.executor.failuresValidityInterval=1h | 指定executor失败重分配次数重置的时间间隔 |
| spark.task.maxFailures=8 | 允许任务执行失败的次数 |
未来改进
- 支持无分区,或非日期分区表。目前只支持日期分区表
- 多数据类型支持,目前为了程序的稳定性,会将Mysql中的字段全部以String类型存储至Hudi
参考资料
https://hudi.apache.org/
欢迎关注我的个人公众号"西北偏北UP",记录代码人生,行业思考,科技评论
原文转载:http://www.shaoqun.com/a/504152.html
coles:https://www.ikjzd.com/w/2506
捷汇:https://www.ikjzd.com/w/419
ApacheHudi使用简介目录ApacheHudi使用简介数据实时处理和实时的数据业务场景和技术选型Apachehudi简介使用AapcheHudi整体思路Hudi表数据结构数据文件.hoodie文件Hudi记录IdCOW和MORCopyOnWriteTableMergeOnReadTable基于hudi的代码实现binlog数据写入Hudi表历史数据同步以及表元数据同步至hive同步历史数据至
一淘比价网:一淘比价网
dmm.adult:dmm.adult
佛罗伦萨旅游攻略 去佛罗伦萨旅游的最佳时间:佛罗伦萨旅游攻略 去佛罗伦萨旅游的最佳时间
深圳海上田园中秋节有表演吗?2020中秋节海上田园演出安排:深圳海上田园中秋节有表演吗?2020中秋节海上田园演出安排
入住酒店未达约定标准 自驾游散伙领队被判退费15万:入住酒店未达约定标准 自驾游散伙领队被判退费15万
No comments:
Post a Comment