一.理解网络爬虫
1.1爬虫的定义
网络爬虫又称为网页蜘蛛、网络机器人。网络爬虫是一种按照一定的规则自动的抓取网络信息的程序或者脚本。通俗的说,就是根据一定的算法实现编程开发,主要通过URL实现数据的抓取和挖掘。
1.2爬虫的类型
根据系统结构和开发技术大致可分为4种类型:
(1)通用网络爬虫,又称为全网爬虫,常见的有百度,Google等。
(2)聚焦网络爬虫,又称主题网络爬虫,是选择性的爬行根据需求的主题相关页面的网络爬虫。
(3)增量式网络爬虫。是指对已下载网页采取增量式更新和只爬行新产生或者已经发生变化的网页的爬虫,它能够在一定程度上保证所爬行的页面尽可能是新的页面。只会在需要的时候爬行新产生或发生更新的页面,并不重新下载没有发生变化的页面,这类爬虫在实际中不太普及。
(4)深层网络爬虫。是大部分内容不能通过静态URL获取的,隐藏在表单后的,只有用户提交一些关键词才能获得的网络页面。
这四类大致又可以分为两类,通用爬虫和聚焦爬虫。聚焦网络爬虫,增量式网络爬虫和深层网络爬虫可归为一类,因为他们是定向爬虫数据。而通用爬虫在网络上称为搜索引擎。
爬虫的设计思路:
(1) 明确需要爬取的网页的URL地址;
(2)通过http请求来获取对应的HTML页面;
(3)提取HTML的内容。若是有用的数据,就保存起来;若是继续爬取的页面,就重新指定第(2)步。
二.爬虫开发基础
2.1 HTTP与HTTPS
http是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。客户端是终端用户,服务器端是网站。通常使用web浏览器,网络爬虫或者其他工具,客户端会发起一个到服务器上指定的http请求。这个客户端就叫做用户代理(User Agent)。一旦收到请求,服务器会发回一个状态行(如"http/1.1 200 OK")和 响应的 消息,其中消息的内容可能是请求的文件,错误消息或者其他消息。
http协议传输的数据都是未加密的,因此使用http协议传输隐私信息非常不安全。
https协议传输的数据都是加密的。在传输数据之前需要客户端与服务端之间进行一次握手,在握手过程中将确立双方加密传输数据的密码信息。
2.2 请求头
请求头描述客户端向服务器发送请求时使用的协议类型,所使用的编码以及发送内容的长度等。检测请求头是常见的反爬虫策略。因为服务器会对请求头做一次检测来判断此次请求是人为的还是非人为的。所以我们在每次发送请求时都添加上请求头。
请求头的参数如下:
(1)Accept:浏览器可以接收的类型
(2)Accept-Charset:编码类型
(3)Accept-Encoding:可以接收压缩编码类型
(4)Accept-Language:可以接收的语言和国家类型
(5)Host:请求的主机地址和端口
(6)Referer:请求来自于那个页面的URL
(7)User-Agent:浏览器相关信息
(8)Cookie:浏览器暂存服务器发送的信息
(9)Connection:http请求版本的特点
(10)Date:请求网站的时间
2.3 cookies
它是指某些网站为了辩护用户身份,进行session跟踪而存储在用户本地终端上的数据。一个cookies就是存储在用户主机浏览器 的文本文件。
服务器可以利用cookies包含的信息判断在http传输中的状态。
2.4 JSON
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
例如:
{"name": "John Doe", "age": 18, "address": {"country" : "china", "zip-code": "10000"}}2.5 JavaScript
JavaScript(简称"JS") 是一种具有函数优先的轻量级,解释型或即时编译型的高级编程语言。是一种解释性脚本语言(代码不进行预编译), 主要用来向HTML(标准通用标记语言下的一个应用)页面添加交互行为。
JavaScript还能根据用户触发某些事件对用户的操作进行加工处理。要在爬虫实现一些功能,就要分析JS如何执行整个用户登录过程。
2.6 Ajax
Ajax 不是一种新的编程语言,而是一种用于创建更好更快以及交互性更强的Web应用程序的技术。使用 JavaScript 向服务器提出请求并处理响应而不阻塞用户核心对象 Ajax 在浏览器与 Web 服务器之间使用异步数据传输(HTTP 请求),这样就可使网页从服务器请求少量的信息,而不是整个页面。判断网页数据是否使用ajax的方法:触发事件之后,判断网页是否发生刷新状态。若网页没有发生刷新,数据就自动生成,说明数据的加载是通过ajax生成并渲染到网页上的。反之,数据是通过服务器后台生成并加载的。
三.Fiddler抓包工具
Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的"进出"Fiddler的数据(指cookie,html,js,css等文件)。
3.1 fiddler安装配置
在官网网站下载(https://www.telerik.com/download/fiddler),界面如下图所示:
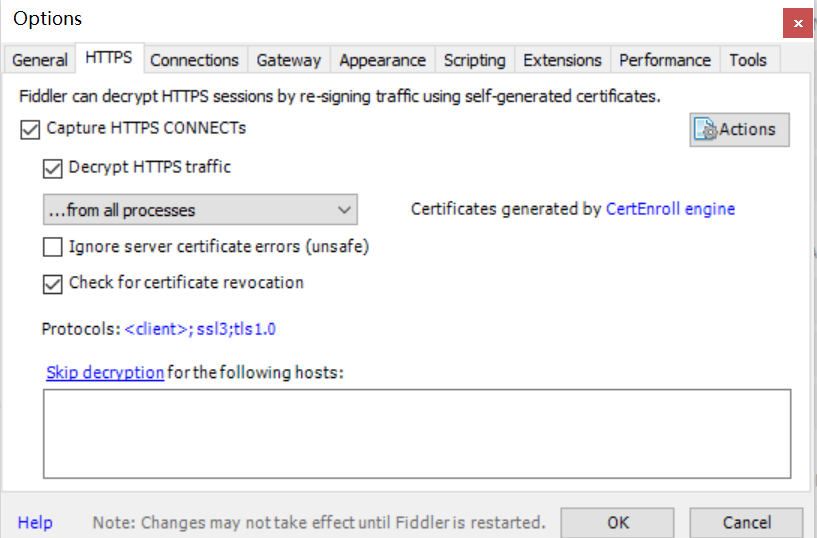
配置fiddler,使其能够抓取https请求信息:
(1)打开菜单-tools-fidder options-https。
(2)勾选https中的选项,然后点击actions-trust root certificate,完成整数验证。
3.2 fiddler抓取手机应用
fiddler可通过同一无线网络实现对手机应用的抓包,手机抓包主要通过远程连接实现手机和fiddler通信。
实现fiddler抓取手机应用的步骤如下:
(1)配置fiddler远程连接模式。打开菜单栏:tools--fiddler options--connections,把allow remote computers to connect勾选上。
(2)在手机端进行参数配置。要连接在同一个IP地址上(cmd中输入ipconfig查看IP地址)
(3)在手机浏览器中输入电脑IP地址和fiddler端口,点击确认后跳转到证书下载页面,点击下载fiddlerroot certificate.
(4)证书文件以cer为后缀名,完成证书安装后,进入手机当前连接WiFi详情,设置代理IP,主机名为电脑IP地址,端口为fiddler配置的端口。

四.开始爬虫
4.1 urllib模块
在python3中不存在urllib2模块,同一为urllib。urllib模块有如下四个子模块:
1 urllib.request:用来打开和读取URL。2 urllib.error:包含了urllib.request产生的异常。3 urllib.parse:用来解析和处理URL。4 urllib.robotparse:用于解析robots.txt文件。
urllib的方法及使用:
1 urllib.urlopen(url[, data[, proxies[,timeout[, context]]]]) 功能说明:urllib是用于访问URL的唯一方法
参数解释:
url :一个完整的远程资源路径,一般是一个网站。 data:默认值为none。若参数data为none,则代表请求方式为get,反之请求方式为post,发送post请求。参数data以字典形式存储数据,并将参数data由字典类型转换成字节类型才能完成post请求。 proxies : 设置代理 timeout:超时设置 context:描述各种SSL选项的实例。
2 urllib.request.Request(url,data=none,headers={},method=none)
功能说明:声明一个request对象,该对象可定义header等请求信息
参数解释:
headers:设置request请求头信息
method:设定请求方式,主要是get和post
"""urllib的使用"""
import urllib.request# 向指定URL发送请求,获取响应。response = urllib.request.urlopen('')# 获取响应内容content = response.read().decode('utf-8')print(content)print(type(response))# 响应码print(response.status)# 响应头信息print(response.headers)
# 导入urllibimport urllib.requesturl = 'https://movie.douban.com/'# 自定义请求头headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Referer': 'https://movie.douban.com/', 'Connection': 'keep-alive'}# 设置request的请求头req = urllib.request.Request(url, headers=headers)# 使用urlopen打开reqhtml = urllib.request.urlopen(req).read().decode('utf-8')# 写入文件f = open('code2.txt', 'w', encoding='utf8')f.write(html)f.close()4.2 requests模块
requests模块是在urllib的基础上做了封装,具备urllib的全部功能,让使用者更加方便的使用。
安装:pip install requests
4.2.1 发出请求
有两种方式:requests.get()和requests.post()方法
1 requests.get(url, params=none, **kwargs)2 requests.post(url, data=none, json=none, **kwargs)
requests提供如下方法获取响应内容:
1 r.status_code:响应状态码(200表示访问成功,4**表示失败) 2 r.raw:原始响应体,使用r.raw.read()读取 3 r.content:字节方式的响应体,需要进行解码 4 r.text:字符串方式的响应体,会自动根据响应头部的字符编码进行解码 5 r.headers:以字典对象存储服务器响应头,若键不存在,则返回none 6 r.json():requests中内置的json解码器 7 r.raise_for_status():请求失败(非200响应),抛出异常 8 r.url:获取请求链接 9 r.cookies:获取请求后的cookies10 r.encoding:获取编码格式
"""使用requests发送请求和携带参数"""import requestsr = requests.get('https://httpbin.org/get') # 发送get请求print(r.text)# 发送post请求,并带参数r = requests.get('https://httpbin.org/get', params={'key1': 'value1', 'key2': 'value2'})print(r.text)# 发送post请求,并传递参数r = requests.post('https://httpbin.org/post', data={'key': 'value'})print(r.text)# 其他HTTP请求类型:PUT,DELETE,HEAD和OPTIONSr = requests.put('https://httpbin.org/put', data={'key': 'value'})print(r.text)r = requests.delete('https://httpbin.org/delete')print(r.text)r = requests.head('https://httpbin.org/get')print(r.text)r = requests.options('https://httpbin.org/get')print(r.text)4.2.2 复杂的请求方式
(1)添加请求头import requestsheaders = { 'content-type': 'application/json', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0'}requests.get("https://www.baidu.com/", headers=headers)(2)使用代理IPimport requestsproxies = { "http": "", "https": "",}requests.get("https://www.baidu.com/", proxies=proxies)(3)证书验证import requestsurl = 'https://kyfw.12306.cn/otn/leftTicket/init'# 关闭证书验证r = requests.get(url, verify=False)print(r.status_code)# 开启证书验证# r = requests.get(url, verify=True)# 设置证书所在路径# r = requests.get(url, verify= '/path/to/certfile')(4)超时设置requests.get("https://www.baidu.com/", timeout=2)requests.post("https://www.baidu.com/", timeout=2)(5)使用cookies
import requeststemp_cookies='JSESSIONID_GDS=y4p7osFr_IYV5Udyd6c1drWE8MeTpQn0Y58Tg8cCONVP020y2N!450649273;name=value'cookies_dict = {}for i in temp_cookies.split(';'): value = i.split('=') cookies_dict [value[0]] = value[1]r = requests.get(url, cookies=cookies)print(r.text)4.2.3 错误和异常
若出现网络问题,则请求将引发connectionerror异常。
若http请求返回不成功的状态码,则将会引发httperror异常。
若请求超时,则会引起超时异常。
若请求超过配置的最大重定向数,则会引发TooManyRedirects异常。
请求显示引发的所有异常都继承自requests.exceptions.RequestException。
4.3 re模块
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
语法请参考:https://www.runoob.com/regexp/regexp-tutorial.html
4.3.1 模块内容
1. re.match(pattern, string[, flags])
这个方法将会从string(我们要匹配的字符串)的开头开始,尝试匹配pattern,一直向后匹配,如果遇到无法匹配的字符,立即返回None,如果匹配未结束已经到达string的末尾,也会返回None。两个结果均表示匹配失败,否则匹配pattern成功,同时匹配终止,不再对string向后匹配。
"""match方法"""import re# match在起始位置匹配ret = re.match('www', 'www.example.com')print(type(ret))# 获取匹配的内容print(ret.group())# 获取匹配内容在原字符串里的下标print(ret.span())# 匹配不成功,返回Noneprint(re.match('com', 'www.example.com'))line = "Cats are smarter than dogs"matchObj = re.match(r'(.*) are (.*?) .*', line, re.M | re.I)if matchObj: print("matchObj.group() : ", matchObj.group()) # 获取第一组的内容 print("matchObj.group(1) : ", matchObj.group(1)) print("matchObj.group(2) : ", matchObj.group(2))else: print("No match!!")
参数说明:• pattern:匹配的正则表达式• string:要匹配的字符串• flags:标志位,用于控制正则表达式的匹配方式,如是否区分大小写,是否多行匹配等。flags参数可选值:• re.I: 忽略大小写(括号内是完整写法,下同)• re.M: 多行模式,改变'^'和'$'的行为(参见上图)• re.S: 点任意匹配模式,改变'.'的行为• re.L: 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定• re.U: 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性• re.X: 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
2. re.search(pattern, string[, flags])
search方法与match方法极其类似,区别在于match()函数只检测re是不是在string的开始位置匹配,search()会扫描整个string查找匹配,match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回None。同样,search方法的返回对象同样match()返回对象的方法和属性。
"""search方法"""import re# search查找第一次出现ret = re.search('www', 'www.aaa.com www.bbb.com')print(type(ret))print(ret.group())print(ret.span())#匹配不成功,返回Noneprint(re.search('cn', 'www.aaa.com www.bbb.com'))line = "Cats are smarter than dogs";searchObj = re.search(r'(.*) are (.*?) .*', line, re.M | re.I)if searchObj: print("searchObj.group() : ", searchObj.group()) print("searchObj.group(1) : ", searchObj.group(1)) print("searchObj.group(2) : ", searchObj.group(2))else: print("Nothing found!!")
3. re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。
"""findall方法"""import re# 查找数字result1 = re.findall(r'\d+','baidu 123 google 456')result2 = re.findall(r'\d+','baidu88oob123google456')print(result1)print(result2)
4. re.finditer(pattern, string[, flags])
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
"""finditer方法"""import re#返回一个迭代器,可以循环访问,每次获取一个Match对象it = re.finditer(r"\d+", "12a32bc43jf3")for match in it: print(match.group())
5. re.split(pattern, string[, maxsplit])
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
6. re.sub(pattern, repl, string, count=0, flags=0)
"""sub方法"""import rephone = "2004-959-559 # 这是一个国外电话号码"# 删除字符串中的 Python注释num = re.sub(r'#.*$', "", phone)print("电话号码是: ", num)# 删除非数字(-)的字符串num = re.sub(r'\D', "", phone)print("电话号码是 : ", num)# 将匹配的数字乘以 2def double(matched): value = int(matched.group('value')) return str(value * 2)s = 'A23G4HFD567'print(re.sub('(?P<value>\d+)', double, s))
参数说明:
1 repl:用于替换的字符串2 string:要被替换的字符串3 count:替换的次数
7. re.subn(pattern, repl, string[, count])
与sub()函数一致,返回结果是一个元组。
8. re.compile(pattern[, flags])
该函数用于编译正则表达式生成一个正则表达式(pattern)对象,供match()和search()等函数使用。
"""compile方法"""import re# 用于匹配至少一个数字pattern = re.compile(r'\d+')# 查找头部,没有匹配m = pattern.match('one12twothree34four')print(m)# 从'e'的位置开始匹配,没有匹配m = pattern.match('one12twothree34four', 2, 10)print(m)# 从'1'的位置开始匹配,正好匹配,返回一个 Match 对象m = pattern.match('one12twothree34four', 3, 10)print(m)# 可省略 0print(m.group(0))
4.4BeautifulSoup4模块
4.4.1 简介
Beautiful Soup,有了它我们可以很方便地提取出 HTML 或
beautifulsoup支持不同的解析器,比如,对HTML解析,对
4.4.2 安装
1 pip install beautifulsoup4
使用时导入:
1 from bs4 import BeautifulSoup
4.4.3 BeautifulSoup库解析器
| 解析器 | 使用方法 | 条件 |
| bs4的HTML解析器 | BeautifulSoup(html,'html.parser') | 安装bs4库 |
| l | BeautifulSoup(html,'l | pip install l |
| l | BeautifulSoup(html,' | pip install l |
| html5lib的解析器 | BeautifulSoup(html,'htmlslib') | pip install html5lib |
4.4.4 使用
"""将字符串解析为HTML文档解析"""from bs4 import BeautifulSouphtml = """<html><head><title>The Dormouse's story</title></head><body><p name="dromouse"><b>The Dormouse's story</b></p><p >Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,<a href="http://example.com/lacie" id="link2">Lacie</a> and<a href="http://example.com/tillie" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p >...</p>"""# 创建BeautifulSoup对象解析html,并使用lsoup = BeautifulSoup(html, 'l')# 格式化输出soup对象的内容print(soup.prettify())
例一:
"""bs4实例测试"""from bs4 import BeautifulSoupimport rehtml = """<html><head><title>The Dormouse's story</title></head><body><p name="dromouse"><b>The Dormouse's story</b></p><p >Once upon a time there were three little sisters; and their names were<a href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,<a href="http://example.com/lacie" id="link2">Lacie</a> and<a href="http://example.com/tillie" id="link3">Tillie</a>;and they lived at the bottom of a well.</p><p >...</p>"""# 创建对象soup = BeautifulSoup(html, 'l')# 获取Tag对象# 查找的是在所有内容中的第一个符合要求的标签print(soup.title)print(type(soup.title))print(soup.p)# 标签的名字print(soup.p.name)# 标签的属性,可获取,也可以设置print(soup.p.attrs)print(soup.p.attrs['class'])# 文本print(soup.p.string)# content属性得到子节点,列表类型print(soup.body.contents)# children属性属性得到子节点,可迭代对象print(soup.body.children)# descendants属性属性得到子孙节点,可迭代对象print(soup.body.descendants)# find_all 查找所有符合要求的 name是按照标签名字查找print(soup.find_all(name='b'))print(soup.find_all(name=['a', 'b']))print(soup.find_all(name=re.compile("^b")))# find_all 查找所有符合要求的 可以按照属性查找,比如这里的id,class# 因为class是关键字,所以使用class_代替classprint(soup.find_all(id='link2'))print(soup.find_all(class_='sister'))# select 查找所有符合要求的 支持选择器print(soup.select('title'))print(soup.select('.sister'))print(soup.select('#link1'))print(soup.select('p #link1'))print(soup.select('a[]'))# 获取内容print(soup.select('title')[0].get_text())
例二:
>>> from bs4 import BeautifulSoup>>> import requests>>> r = requests.get("http://python123.io/ws/demo.html")>>> demo = r.text>>> demo'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p ><b>The demo python introduces several python courses.</b></p>\r\n<p >Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>\r\n</body></html>'>>> soup = BeautifulSoup(demo,"html.parser")>>> soup.title #获取标题<title>This is a python demo page</title>>>> soup.a #获取a标签<a href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>>>> soup.title.string'This is a python demo page'>>> soup.prettify() #输出html标准格式内容'<html>\n <head>\n <title>\n This is a python demo page\n </title>\n </head>\n <body>\n <p >\n <b>\n The demo python introduces several python courses.\n </b>\n </p>\n <p >\n Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\n <a href="http://www.icourse163.org/course/BIT-268001" id="link1">\n Basic Python\n </a>\n and\n <a href="http://www.icourse163.org/course/BIT-1001870001" id="link2">\n Advanced Python\n </a>\n .\n </p>\n </body>\n</html>'>>> soup.a.name #每个<tag>都有自己的名字,通过<tag>.name获取'a'>>> soup.p.name'p'>>> tag = soup.a>>> tag.attrs{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}>>> tag.attrs['class']['py1']>>> tag.attrs['href']'http://www.icourse163.org/course/BIT-268001'>>> type(tag.attrs)<class 'dict'>>>> type(tag)<class 'bs4.element.Tag'>五.更多数据提取的方式
5.1 XPath和l 5.1.1
https://www.runoob.com/
5.1.2 xpath
参考:https://www.runoob.com/xpath/xpath-tutorial.html
5.1.3 l
传输和存储数据,HTML被设计用来显示数据。这两个都是树形结构,可以先将HTML文件转换成l
# lpip install l# 使用(1)"""将字符串解析为HTML文档"""from limport etreetext='''<div><ul><li><ahref="link1.html">firstitem</a></li><li><ahref="link2.html">seconditem</a></li><li><ahref="link3.html">thirditem</a></li><li><ahref="link4.html">fourthitem</a></li><li><ahref="link5.html">fifthitem</a></ul></div>'''#利用etree.HTML,将字符串解析为HTML文档html=etree.HTML(text)#按字符串序列化HTML文档result=etree.tostring(html).decode('utf-8')print(result)(2)"""读文件"""from limport etree# 读取外部文件hello.htmlhtml = etree.parse('./data/hello.html')# pretty_print=True表示格式化,比如左对齐和换行result = etree.tostring(html, pretty_print=True).decode('utf-8')print(result)
原文转载:http://www.shaoqun.com/a/494435.html
eori:https://www.ikjzd.com/w/499
海豚村:https://www.ikjzd.com/w/1779
谷歌趋势:https://www.ikjzd.com/w/397
一.理解网络爬虫1.1爬虫的定义网络爬虫又称为网页蜘蛛、网络机器人。网络爬虫是一种按照一定的规则自动的抓取网络信息的程序或者脚本。通俗的说,就是根据一定的算法实现编程开发,主要通过URL实现数据的抓取和挖掘。1.2爬虫的类型根据系统结构和开发技术大致可分为4种类型:(1)通用网络爬虫,又称为全网爬虫,常见的有百度,Google等。(2)聚焦网络爬虫,又称主题网络爬虫,是选择性的爬行根据需求的主题相
zappos.com:zappos.com
haofang:haofang
预计四年后,亚马逊印度的电子商务市场份额将达到35%:预计四年后,亚马逊印度的电子商务市场份额将达到35%
深度干货 | CPC低成本强关联,BestSeller最新打法:深度干货 | CPC低成本强关联,BestSeller最新打法
紫云花汐什么时候去最好?紫云花汐庄园最佳观赏时间?:紫云花汐什么时候去最好?紫云花汐庄园最佳观赏时间?
No comments:
Post a Comment