
前言
本篇文章收录于专辑 id="前情回顾">前情回顾
在正式讲解套路之前,我们先回忆一下前面几节讲到的内容。
在第2节,我们学习了渐近分析法,将算法的复杂度与输入规模挂钩,随着输入规模的增大,算法执行的时间将呈现一种什么样的趋势,将这个趋势用函数表示,再去除低阶项和常数项,就得到了算法的时间复杂度。
在第3节,我们分别从最坏、平均、最好三种情况来分析了算法的复杂度,得出结论,一般使用最坏情况来评估算法的复杂度。
在第4节,我们通过动态数组的插入元素及经典快速排序的时间复杂度,解释了有的时候不能使用最坏情况来评估算法的复杂度。
在第5节,我们从读音、数学、通俗理解三个方面分析了各种表示算法复杂度的符号,得出结论还是使用大O比较香,大O代表了算法的上界,它与前面讲到的最坏情况往往是对应的。
所以,这里所说的套路也是针对大部分情况,也就是最坏情况,对于一些个例,比如经典快排,我们虽然也是使用大O表示他们的复杂度,但是,其实是一种均摊的复杂度。
好了,让我们看看计算算法复杂度的套路到底是什么吧。
套路
我将计算算法复杂度的套路归纳为以下五步:
- 明确输入规模n;
- 考虑最坏情况或均摊情况,如果最坏情况为个例,那就是均摊;
- 计算算法执行的次数与n的关系,并用函数表示出来;
- 去除低阶项;
- 去除常数项;
比如,对于在数组中查找指定元素的操作:
- 输入规模为数组的长度n;
- 考虑最坏情况为目标元素不在数组中;
- 算法的执行次数为遍历所有数组元素,也就是n次,用函数表示f(n) = n;
- 去除低阶项,没有低阶项,还是n;
- 去除常数项,没有常数项,还是n;
所以,在数组中查找指定元素的时间复杂度为O(n)。
OK,使用这种方式可以很快的计算出算法的复杂度,也不需要进行额外的计算,非常快捷高效。
常见的复杂度
上面我们说了,复杂度的计算就是计算与输入规模n的关系,所以,我们想想数学中关于n的函数就能得出常见的复杂度了,我绘制了一张表格:
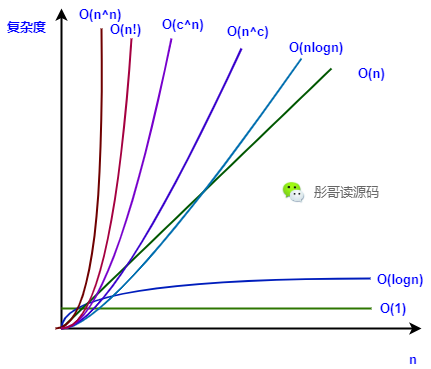
与n的关系 英文释义 复杂度 示例 常数(不相关) Constant O(1) 数组按索引查找元素 对数相关 Logarithmic O(logn) 二分查找 线性相关 Linear O(n) 遍历数组的元素 超线性相关 Superlinear O(nlogn) 归并排序、堆排序 多项式相关 Polynomial O(n^c) 冒泡排序、插入排序、选择排序 指数相关 Exponential O(c^n) 汉诺塔 阶乘相关 Factorial O(n!) 行列式展开 n的n次方 无 O(n^n) 不知道有没有这种算法 在这张表中,复杂度是依次增加的,可以看到常数复杂度O(1)无疑是最好的,让我们用一张图来直观感受下:
后记
本节,我们一起学习了复杂度分析的套路以及常见的复杂度,到目前为止,我们不管是举例还是讲解基本上都在说时间复杂度。
那么,空间复杂度又是什么呢?空间与时间之间如何权衡呢?
下一节,我们接着聊。
复杂度分析的套路及常见的复杂度亚马逊全球开店、 吉祥邮、 敦煌网、 2020年斋月期间,跨境电商需要重点注意什么?2020年斋月重点关注什么?、 不套路!亚马逊ppc问题汇总!、 亚马逊卖家如何制定有效的出价策略?、 12月份去哪里旅游 浙江雁荡山:地质称奇、 走进埃及 找寻千年未央的记忆(全文)、 云南腾冲:极边古镇的生活引力和诱惑(全文)、关注公号主"彤哥读源码",解锁更多源码、基础、架构知识。
No comments:
Post a Comment